Regresi Linear Sederhana
Di dalam bidang ilmu pengetahuan dan teknologi, sering dijumpai hubungan antara dua variabel.
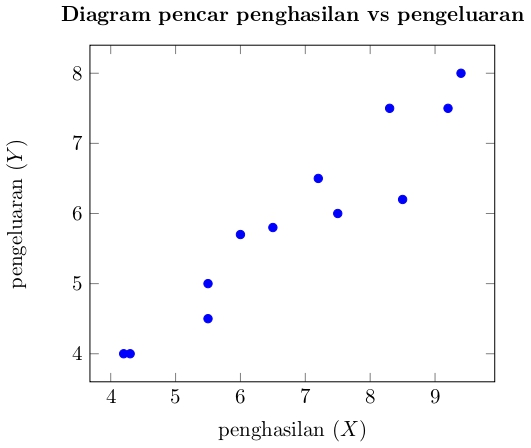
Sebagai contoh, "hubungan antara besarnya penghasilan dengan besarnya pengeluaran".
Dalam contoh ini hal ini, variabel pengeluaran tergantung pada variabel penghasilan. Oleh karena itu
- penghasilan dinamakan
variabel bebas atauvariabel penjelas - pengeluaran dinamakan
variabel tak bebas atauvariabel respon
Untuk selanjutnya,
- $X$ notasi untuk variabel bebas dan
- $Y$ notasi untuk variabel tak bebas.
Contoh
Misalnya dilakukan observasi terhadap 12 orang untuk mendapatkan data penghasilan dan pengeluaran. Hasil observasi dinyatakan dalam tabel berikut (dalam jutaan rupiah).| Penghasilan ($X$) | 5.5 | 7.5 | 4.3 | 9.4 | 8.5 | 6.0 | 9.2 | 7.2 | 5.5 | 4.2 | 6.5 | 8.3 |
| Pengeluaran ($Y$) | 4.5 | 6.0 | 4.7 | 8.0 | 6.2 | 5.7 | 7.5 | 6.5 | 5.0 | 4.0 | 5.8 | 7.5 |
- $Y_i$ nilai variabel tak bebas observasi ke-$i$
- $X_i$ nilai variabel bebas observasi ke-$i$
- $\alpha$ suatu konstanta yang disebut intersep
- $\beta$ juga konstanta yang dinamakan slope/kemiringan
- $\varepsilon_i$ dinamakan kesalahan random observasi ke-$i$ yang nilainya tidak diketahui, dan diasumsikan berdistribusi normal standar.
Estimasi $\alpha$ dan $\beta$
Untuk memprediksi nilai $\alpha$ dan $\beta$ pada persamaan regresi tersebut, perlu dilakukan observasi sehingga diperoleh data berpasangan \[ (X_1,Y_1), (X_2, Y_2), \cdots, (X_n,Y_n).\] Tentu kita menghendaki agar suku kesalahan $\epsilon_i$ pada persaman regresi dibuat sekecil mungkin. Ada suatu metoda di dalam matematika untuk mencari parameter ini sehingga jumlah kuadrat kesalan randomnya adalah minimal, yaitu least square method (metode kuadrat terkecil). Dengan menggunakan metode ini, dapat ditunjukkan bahwa nilai parameter $\alpha$ dan $\beta$ dapat diestimasi dengan menggunakan rumus:
Contoh
Berikut ini contoh untuk mencari persamaan regresi untuk menjelaskan hubungan antara penghasilan ($X$) dan pengeluaran ($Y$) pada contoh di atas.Untuk memudahkan prediksi paramater $\alpha$ dan $\beta$ tersebut, perhitungan dilakukan dengan bantuan tabel berikut:
| Observasi ke $i$ | $X$ | $Y$ | $XY$ | $X^2$ |
| 1 | 5.5 | 4.5 | 24.75 | 30.25 |
| 2 | 7.5 | 6 | 45 | 56.25 |
| 3 | 4.3 | 4 | 17.2 | 18.49 |
| 4 | 9.4 | 8 | 75.2 | 88.36 |
| 5 | 8.5 | 6.2 | 52.7 | 72.25 |
| 6 | 6 | 5.7 | 34.2 | 36 |
| 7 | 9.2 | 7.5 | 69 | 84.64 |
| 8 | 7.2 | 6.5 | 46.8 | 51.84 |
| 9 | 5.5 | 5 | 27.5 | 30.25 |
| 10 | 4.2 | 4 | 16.8 | 17.64 |
| 11 | 6.5 | 5.8 | 37.7 | 42.25 |
| 12 | 8.3 | 7.5 | 62.25 | 68.89 |
| Jumlah | 82.1 | 70.7 | 509.1 | 597.11 |
-
Dari baris terakhir tabel tersebut diperoleh:
- $\sum_{i=1}^{12}X_i = 82.1$
- $\sum_{i=1}^{12}Y_i =70.7$
- $\sum_{i=1}^{12}X_iY_i =509.1$
- $\sum_{i=1}^{12}X^2_i =597.11$
- $n = 12$
- $\overline{X}=82.1/12=6.84$
- $\overline{Y}=70.7/12=5.89$
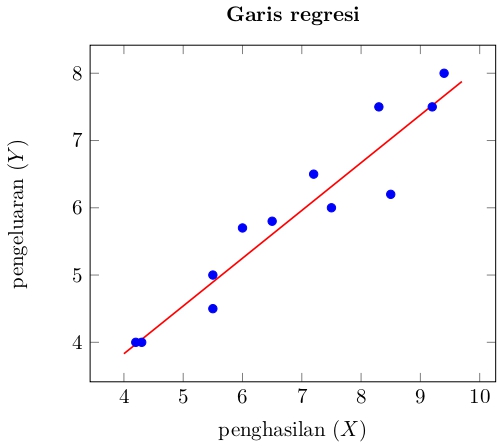
Oleh karena itu \[ \hat{\beta}=\frac{\sum_{i=1}^nX_iY_i-\overline{X}\sum_{i=1}^nY_i}{\sum_{i=1}^nX_i^2-n\overline{X}^2}= \frac{509.1-(6.84)\cdot (70.7)}{597.11-(12)\cdot (6.84)^2}=0.7150,\] \[\hat{\alpha}= \overline{Y}-\hat{\beta}\overline{X}= 5.89-(0.7150)\cdot 6.84 = 0.9994.\]
Dengan demikian estimasi persamaan regresinya adalah \[ \hat{Y} = 0.9994 + 0.7150 X.\]
Manfaat persamaan ini diantaranya untuk memprediksi pengeluaran untuk pendapatan tertentu. Misalnya untuk penghasilan $10$ juta, nilai prediksi pengeluarannya adalah \[ \hat{Y}= 0.9994 + (0.7150)\cdot(10)= 8.15 \; juta\; rupiah.\]
| Obervasi ke | Pendapatan ($X_i$) | Nilai observasi ($Y_i$) | Nilai prediksi ($\hat{Y}_i$) | Residual ($e_i$) | |
|---|---|---|---|---|---|
| 1 | 5.5 | 4.5 | 4.895 | -0.395 | |
| 2 | 7.5 | 6 | 6.315 | -0.315 | |
| 3 | 4.3 | 4 | 4.043 | -0.043 | |
| 4 | 9.4 | 8 | 7.664 | 0.336 | |
| 5 | 8.5 | 6.2 | 7.025 | -0.825 | |
| 6 | 6 | 5.7 | 5.25 | 0.45 | |
| 7 | 9.2 | 7.5 | 7.522 | -0.022 | |
| 8 | 7.2 | 6.5 | 6.102 | 0.398 | |
| 9 | 5.5 | 5 | 4.895 | 0.105 | |
| 10 | 4.2 | 4 | 3.972 | 0.028 | |
| 11 | 6.5 | 5.8 | 5.605 | 0.195 | |
| 12 | 8.3 | 7.5 | 6.883 | 0.617 |
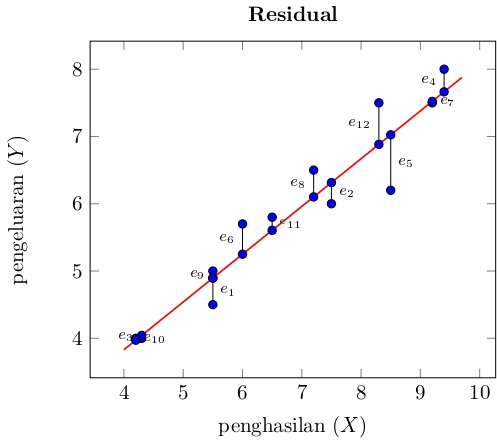
Deviasi nilai obvervasi terhadap rata-rata observasi adalah \[Y_i - \bar{Y}\] Jumlah kuadrat dari deviasi ini dinamakan jumlah kuadrat total (SST=total sum of square), yakni \[ SST = \sum_{i=1}^n (Y_i - \bar{Y})^2.\] Kuantitas $SST$ ini menggambarkan variasi antara nilai observasi $Y_i$. Semakin besar nilai $SST$ berarti semakin bervariari nilai $Y_i$.
Nilai $SST$ dapat dipartisi menjadi dua bagian sebagai berikut. \begin{eqnarray} SST &=& \sum_{i=1}^n (Y_i - \bar{Y})^2\\ &=& \sum_{i=1}^n [(Y_i - \hat{Y})+(\hat{Y}-\bar{Y})]^2\\ &=& \sum_{i=1}^n (Y_i - \hat{Y})^2+\sum_{i=1}^n(\hat{Y}-\bar{Y})^2+2\sum_{i=1}^n(Y_i - \hat{Y})(\hat{Y}-\bar{Y})\\ &=& \sum_{i=1}^n (Y_i - \hat{Y})^2+\sum_{i=1}^n(\hat{Y}-\bar{Y})^2\\ &=& SSE + SSR \end{eqnarray} dimana $SSR=\sum_{i=1}^n(\hat{Y}-\bar{Y})^2$ dinamakan jumlah kuadrat regresi (regression sum of square).
Mean square error (MSE) didefinisikan \[ MSE = \frac{SSE}{n-2},\] $n-2$ dinamakan derajat bebas.
Sifat estimator $\hat{\beta}$ dan $\hat{\alpha}$
Dapat ditunjukkan bahwa nilai harapan dari $\hat{\beta}$ dan $\hat{\alpha}$ berturut-turut adalah \begin{eqnarray*} E(\hat{\beta}) = \beta \\ E(\hat{\alpha})=\alpha \end{eqnarray*} Dengan demikian $\hat{\beta}$ dan $\hat{\alpha}$ masing-masing merupakan estimator tak bias untuk parameter $\beta$ dan $\alpha$. Untuk mengetahui variabilitas kedua estimator, dapat dipelajari melalui varian kedua estimator. Varian $\hat{\beta}$ dan $\hat{\alpha}$ adalah \begin{eqnarray*} Var(\hat{\beta}) = \frac{\sigma^2}{\sum x_i^2 -n\bar{x}^2} \\ Var(\hat{\alpha})=\frac{\sigma^2 \sum x_i^2}{n(\sum x_i^2-n\bar{x}^2)} \end{eqnarray*} Selisih antara nilai respon $Y_i$ dengan nilai prediksi $\hat{Y_i}$ dinamakan residual, \[\text{residual}=Y_i-\hat{\alpha}-\hat{\beta} x_i \] Untuk mengukur seberapa besar penyimpangan nilai respon terhadap prediksi diambil jumlah kuadrat residual. Jumlah kuadrat residual, ditulis $SSR$ adalah \[SSR = \sum \left(Y_i-\hat{\alpha} - \hat{\beta} x_i \right)^2 \] Dapat dibuktikan bahwa \[\frac{SSR}{\sigma^2} \] berdistribusi chi-square dengan derajat bebas $n-2$. Oleh karena itu nilai harapan $SSR/(n-2)$ adalah \[ E\left( \frac{SSR}{(n-2)} \right) = \sigma^2\] yang berarti $\frac{SSR}{(n-2)}$ merupakan estimator tak bias untuk parameter $\sigma^2$.Untuk pembahasan selanjutnya, akan digunakan notasi berikut: \begin{eqnarray*} S_{xx}&= \sum_{i=1}^n (x_i-\bar{x})^2=\sum_{i=1}^n x^2_i -n\bar{x}^2 \\ S_{yy}&= \sum_{i=1}^n (y_i-\bar{y})^2=\sum_{i=1}^n y^2_i -n\bar{y}^2 \\ S_{xy}&= \sum_{i=1}^n (x_i-\bar{x}) (y_i-\bar{y})=\sum_{i=1}^n x_iy_i -n\bar{x}\bar{y}\\ \end{eqnarray*}
Inferensi tentang parameter $\beta$ dan $\alpha$
Karena $\hat{\beta}$ merupakan estimator, maka bisa dibentuk interval kepercayaan parameter $\beta$. Interval kepercayaan $100(1-\alpha)$ persen untuk $\beta$ diberikan oleh \[ \left( \hat{\beta}-t_{\alpha/2,n-2} \sqrt{\frac{SSR}{(n-2)S_{xx}}},\: \hat{\beta}+t_{\alpha/2,n-2} \sqrt{\frac{SSR}{(n-2)S_{xx}}} \right) \] Di dalam persamaan regresi \[y=\alpha+\beta x + e \] penting untuk menguji hipotesis apakah $\beta$ sama dengan $0$, yaitu \[H_0: \beta=0 \quad \textnormal{melawan} \quad H_1:\beta \neq 0 \] pada tingkat signifikansi $\alpha$. Untuk menguji $H_0$ pada tingkat signifikansi $\alpha$ digunakan statistik penguji \[t=\sqrt{\frac{(n-2)S_{xx} }{SSR}\beta }\] dimana $H_0$ diterima jika $|t| \leq t_{\alpha/2,n-2}$ dam ditolak jika $|t| > t_{\alpha/2,n-2}$.\\ Interval kepercayaan untuk parameter intersep $\alpha$ adalah \begin{equation} \left( \hat{\alpha} - \sqrt{\frac{\sum x_i^2 SSR}{n(n-2)S_{xx}}} t_{\alpha/2, n-2},\: \hat{\alpha} + \sqrt{\frac{\sum x_i^2 SSR}{n(n-2)S_{xx}}} t_{\alpha/2, n-2} \right) \end{equation}Koefisien Determinasi
Persamaan regresi yang telah diperoleh perlu diselidiki seberapa besar persamaan tersebut mampu menjelaskan data yang sebenarnya. Berdasarkan data $(X_1,Y_1),(X_2,Y_2),\cdots ,(X_n,Y_n)$, bisa dicari variasi variabel respon $Y$ yang disebabkan pengaruh variabel penjelas $X$. Variasi variabel $Y$ didefinisikan oleh \begin{equation} S_{yy}=\sum_{i=1}^n(Y_i-\bar{Y})^2 \end{equation} Karena $Y=\alpha + \beta X + \epsilon$, maka variasi $Y$ disebabkan oleh dua komponen, yaitu
- komponen variasi yang disebabkan oleh variabel bebas $X$
- komponen variasi yang disebabkan oleh faktor kesalahan random $\epsilon$ .
variasi yang disebabkan oleh variabel penjelas $X$ = variasi $Y$ - variasi oleh kesalahan random.
- $SSR = \sum \left(Y_i - \hat{Y}\right)^2=\sum \left(Y_i-\hat{\alpha} - \hat{\beta} X_i \right)^2$
- $S_{yy}=\sum_{i=1}^n(Y_i-\bar{Y})^2$.
Semakin besar nilai $R^2$, semakin baik persamaan regresi tersebut mampu menjelaskan data yang sebenarnya.
Contoh
Pada contoh ini akan dicari nilai koefisien determinasi pada contoh di atas. Proses perhitungannya bisa menggunakan tabel berikut:| $X$ | $Y$ | $\hat{Y}$ | $(Y-\hat{Y})^2$ | $(Y-\overline{Y})^2$ |
| 5.5 | 4.5 | 4.93 | 0.1849 | 1.9321 |
| 7.5 | 6 | 6.3619 | 0.131 | 0.0121 |
| 4.3 | 4 | 4.0739 | 0.0055 | 3.5721 |
| 9.4 | 8 | 7.7204 | 0.0782 | 4.4521 |
| 8.5 | 6.2 | 7.0769 | 0.769 | 0.0961 |
| 6 | 5.7 | 5.2894 | 0.1686 | 0.0361 |
| 9.2 | 7.5 | 7.5774 | 0.006 | 2.5921 |
| 7.2 | 6.5 | 6.1474 | 0.1243 | 0.3721 |
| 5.5 | 5 | 4.9319 | 0.0046 | 0.7921 |
| 4.2 | 4 | 4.0024 | 0 | 3.5721 |
| 6.5 | 5.8 | 5.6469 | 0.0234 | 0.0081 |
| 8.3 | 7.5 | 6.9339 | 0.3205 | 2.5921 |
| Jumlah | 1.816 | 20.0292 |
Dengan demikian nilai koefisien determinasi adalah \[ R^2=1 - \frac{SSR}{S_{yy}}=1-\frac{1.816 }{20.0292}=0.9093,\] yang berarti bahwa persamaan regresi yang telah diperoleh di atas bisa menjelaskan data sebenarnya sebesar 90.90 %.
Korelasi
Korelasi merupakan ukuran keeratan hubungan antara dua variabel. Di dalam korelasi tidak dipersoalkan hubungan sebab akibat. Dengan demikian pernyataan "korelasi antara variabel $X$ dan $Y$" sama saja dengan pernyataan "korelasi antara variabel $Y$ dan $X$".
Keeratan hubungan antara dua variabel dinyatakan dengan koefisien korelasi. Jika $(x_1,y_1), (x_2,y_2), \cdots , (x_n,y_n)$ adalah data sampel, maka koefisien korelasi antara variabel $X$ dan $Y$, ditulis $r$, didefinisikan \begin{equation} r=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum_{i=1}^n(x_i-\bar{x})^2 \sum_{i=1}^n(y_i-\bar{y})^2}} \label{korelasi} \end{equation}
Nilai koefisien korelasi adalah antara $-1$ sampai dengan $1$, yakni \[-1 \leq r \leq 1 .\]
Variabel $X$ dan $Y$ dikatakan:
- berkorelasi positif jika $r>0$,
- berkorelasi negatif jika $r \lt 0$,
- tidak berkorelasi jika $r=0$.
Contoh
Berikut data berat badan ($X$) dan tinggi badan ($Y$) sepuluh orang dewasa:| Berat badan (kg) | 60 | 63 | 57 | 61 | 72 | 75 | 56 | 50 | 67 | 64 |
| Tinggi badan (cm) | 162 | 168 | 165 | 170 | 168 | 170 | 155 | 160 | 164 | 168 |
Tabel berikut merupakan proses perhitungan untuk mencari koefisien korelasi antara berat badan dan tinggi badan:
| No. | $X$ | $Y$ | $X-\overline{X}$ | $Y-\overline{Y}$ | $(X-\overline{X})^2$ | $(Y-\overline{Y})^2$ | $(X-\overline{X})(Y-\overline{Y})$ |
| 1 | 60 | 162 | -2.5 | -3 | 6.25 | 9 | 7.5 |
| 2 | 63 | 168 | 0.5 | 3 | 0.25 | 9 | 1.5 |
| 3 | 57 | 165 | -5.5 | 0 | 30.25 | 0 | 0 |
| 4 | 61 | 170 | -1.5 | 5 | 2.25 | 25 | -7.5 |
| 5 | 72 | 168 | 9.5 | 3 | 90.25 | 9 | 28.5 |
| 6 | 75 | 170 | 12.5 | 5 | 156.25 | 25 | 62.5 |
| 7 | 56 | 155 | -6.5 | -10 | 42.25 | 100 | 65 |
| 8 | 50 | 160 | -12.5 | -5 | 156.25 | 25 | 62.5 |
| 9 | 67 | 164 | 4.5 | -1 | 20.25 | 1 | -4.5 |
| 10 | 64 | 168 | 1.5 | 3 | 2.25 | 9 | 4.5 |
| Jumlah | 625 | 1650 | 506.5 | 212 | 220 |
Nilai koefiisien korelasinya adalah \[ r=\frac{220}{\sqrt{(506.5)\cdot (212)}}=0.6723.\] Ini berarti terdapat korelasi positif antara berat badan dan tinggi badang, dengan tingkat keeretan hubungan 67.23%.
Korelasi dan koefisien determinasi
Persamaan \ref{korelasi} dapat dituliskan sebagai \begin{equation} r=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum_{i=1}^n(x_i-\bar{x})^2 \sum_{i=1}^n(y_i-\bar{y})^2}} =\frac{S_{xy}}{\sqrt{S_{xx}S_{yy}}} \end{equation} Karena $SSR=\frac{S_{xx}S_{yy}-S^2_{xy}}{S_{xx}}$, maka \begin{eqnarray*} r^2&=&\frac{S^2_{xy}}{S_{xx}S_{yy}}\\ &=&\frac{S_{xx} S_{yy}-SSR S_{xx}}{S_{xx}S_{yy}}\\ &=&1-\frac{SSR}{S_{yy}}\\ &=&R^2, \end{eqnarray*} yakni \[|r|=\sqrt{R^2} \] Ini berarti nilai absolut koefisien korelasi sama dengan akar dua koefisien determinasi. Tanda $r$ sama dengan tanda koefisien $\hat{\beta}$ didalam persamaan regresi.